关于矢量瓦片技术支持前端渲染带来的思考
前言
书接上回,此前提到地图瓦片切片技术的发展。矢量切片技术将瓦片的渲染由服务端迁移到客户端,此操作带来的影响力不可谓不大,基于此,完全可以随心所欲的定义地图的表达。那么在实际的应用当中,当渲染从服务端迁移至客户端后,是否会带来一些其他的问题?
超20M的瓦片数据
此事发生在2023年,当时我们的技术组合是:空间数据库+GeoServer(vector tile plugin)+ Mapbox GL JS,基于此提供矢量瓦片服务。某一天,在某位心细如发的大佬的察觉下,突然发现提供的地图服务在层级为10级时,出现一个大小大于20M的瓦片,顿感惊人。经过多次核对后,确定在该份数据下,GeoServer在小比例尺下(约莫10级往下)生产的大部分瓦片尺寸都比较大,而数据密度越大的地方尤其严重。最终,我们认为:是由于GeoServer没有提供矢量分层抽稀简化的能力,所以导致在小比例尺+高密度的双重叠加下,瓦片大小暴增。
在一段时间后,为了快速处理该问题,我曾提出。可以基于目前配图的思想(解析配图文件),在服务端去往数据库读取数据的时候便进行数据过滤(其实就是分层分级),避免大量不需要的数据经查询、传输、编码再传输带来的影响。比如我们按照口径进行约定,在13级往下,只显示大于xx口径的数据的数据,那么此时所有小于该口径的数据都不需要被传递
但我们前端配图人员提出一个说法:说如果你这般处理,那么意味着配图的时候数据就不是完整的,我无法自行选择数据,不同的项目需求也不尽相同,灵活性自然大打折扣。同时,也就意味着该项配置与瓦片缓存是绑定的,一旦存在配图项的变更,便意味着此前缓存均是失效的。
配图的边界
时至今日,已过半年。目前想来,这里确定存在这么几个问题:
- 到底什么是配图,配图配的又是什么?
- 数据发布过程中,配图应该处于什么阶段?
对于什么是配图,我目前还给不出一个十分恰当的回答,因为此前确定没有做过这方面的内容。但私以为狭义情况下,地图的符号化过程应该称之为配图。配图内容如下:
- 要素符号化
- 文字标注
那么分层显示控制能力(属性分级)是否应该归属到配图中呢?在图像切片时代中,想来配图都是提前确定好的,而且受益于影像金字塔自带多层次分辨率的能力,所以在配图中压根不需要考虑分级问题(假定数据都是栅格数据)。但是矢量数据并没有分辨率的说法,所以无法从影像金字塔模型获利。在面对大数据量或高密度区域的情况时,需自行处理分级问题。
对于矢量数据来说,在矢量瓦片技术出现之前,所有瓦片都是在服务端渲染,那么属性分级控制也是在服务端进行的。而在矢量瓦片技术出现之后,完全可以直接在客户端实现属性分层控制了。且目前开源GIS技术方案大多都选择:GeoServer+Mapbox,但在实际使用中感觉GeoServer并不理会什么属性分级和空间特征简化,而是一股脑的将数据丢给客户端,客户端自己筛选。
从结果来看,好像在应用上确实是行得通的。实际上确实如此,或许大多数公司都是这样做的吧。但是我认为这是有问题的,这就好像是得益于矢量瓦片渲染能力后移的特点,服务端将原本应该自己管控的数据一股脑的丢到了客户端,由客户端自行控制。
那么问题来了,数据的分层分级控制权到底应该给谁,是瓦片生产端还是客户端呢?
我认为应该优先厘清整个生产流程,明确各节点能力边界
- 数据的分类、分层肯定是在最前面,且分类、分层与金字塔分层息息相关。且应该形成公知,瓦片的生产段与应用的客户端都应该清晰的知道【数据分层分级控制策略 → 矢量金字塔分层规则定义】
- 其次是矢量数据的发布,此中应该完整的实现矢量数据分层,即形成矢量金字塔结构【矢量金字塔模型实现】
- 因矢量瓦片技术带来的配图后置,数据的符号化在此处完成【地图符号化】
其次,可以想一下数据分层控制权限归属到客户端后会带来什么样的影响:
- 在大数据量或高密度区域的情况下,小比例尺级别瓦片尺寸可能爆炸
- 计算资源、存储资源(缓存)占用增多
- 对带宽要求高,移动端的话流量嗖嗖的跑
- 客户端性能下降
所以我认为,数据控制能力应该归属于瓦片生产端,客户端可以支持分层控制能力,但其对于数据的控制只能在全局统计的分类、分层策略所提供的范围内活动。也就是说客户端可以实现的分层范围时全局规定的范围的子集。
对于目前在配图中进行全局数据的分层分级行为,我认为是矢量瓦片技术带来的配图动作后置产生的影响。同时在GeoServer + Mapbox 客户端控制数据操作的长期影响下,给后来人一种错觉便是数据控制也变更到客户端控制。
论GeoServer的正确使用?
最近在自己实现一个矢量瓦片服务,由于自己目前只会写Java,所以不得不对GeoServer进行借鉴,所以就进一步的研究了GeoServer的源码。
GeoServer可以看作是GeoTools,GeoWebCache以及OGC API Implement的结合体。其中,GeoWebCache提供了金字塔结构的定义和缓存能力;GeoTools提供了空间数据相关的定义和操作。在本次研究后,我确定我需要向GeoServer道歉。在此前的描述中,我认为GeoServer是没有提供数据分层和空间简化的能力的,但是我错了。
我拉取的是GeoServer的2.22.x分支,应为这个版本用的比较多,相对而言更具有代表性,所以没有选择最新版本。
空间简化能力
也就是说,在GeoServer vector tile的生产过程中,已经集成了Simplify功能。
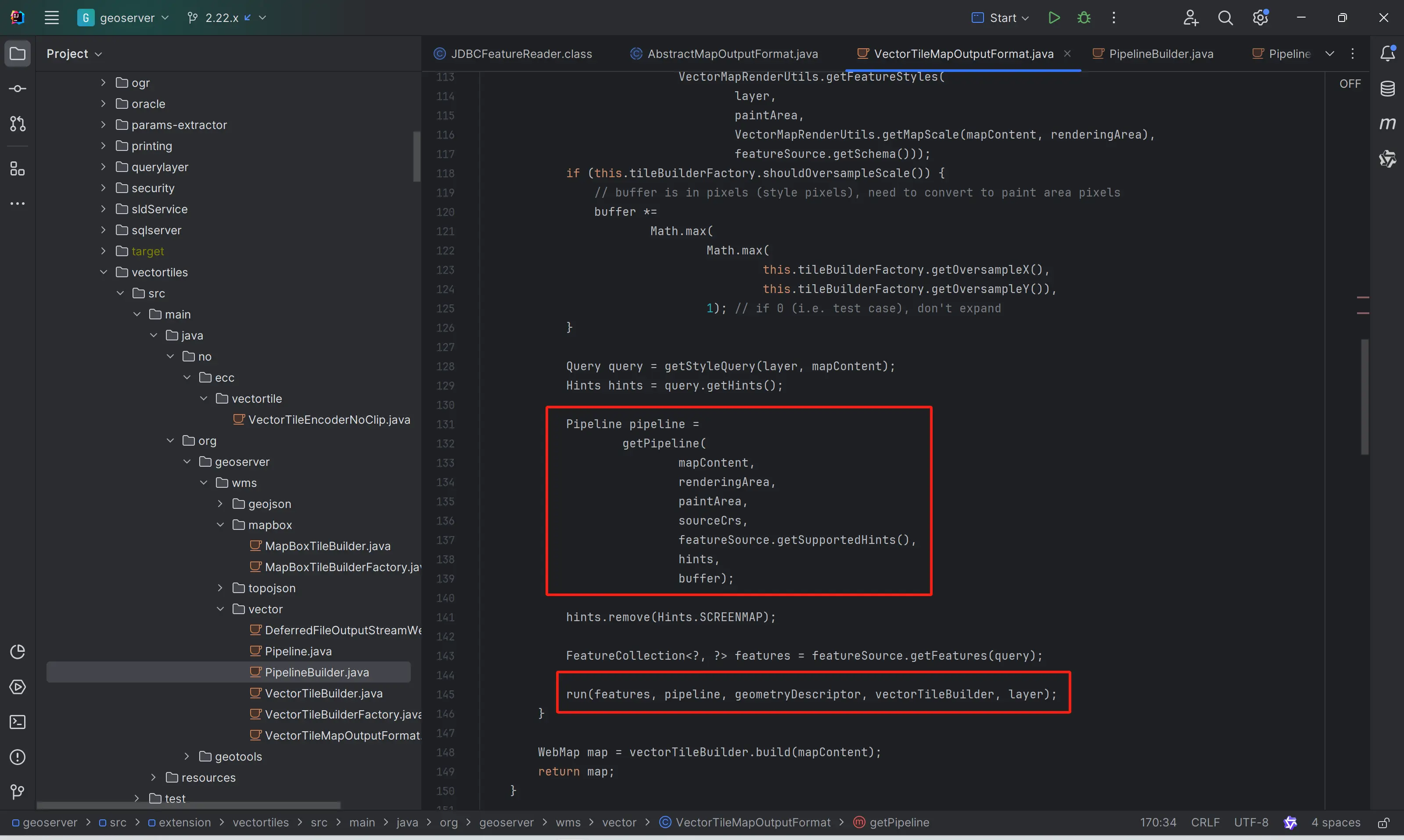
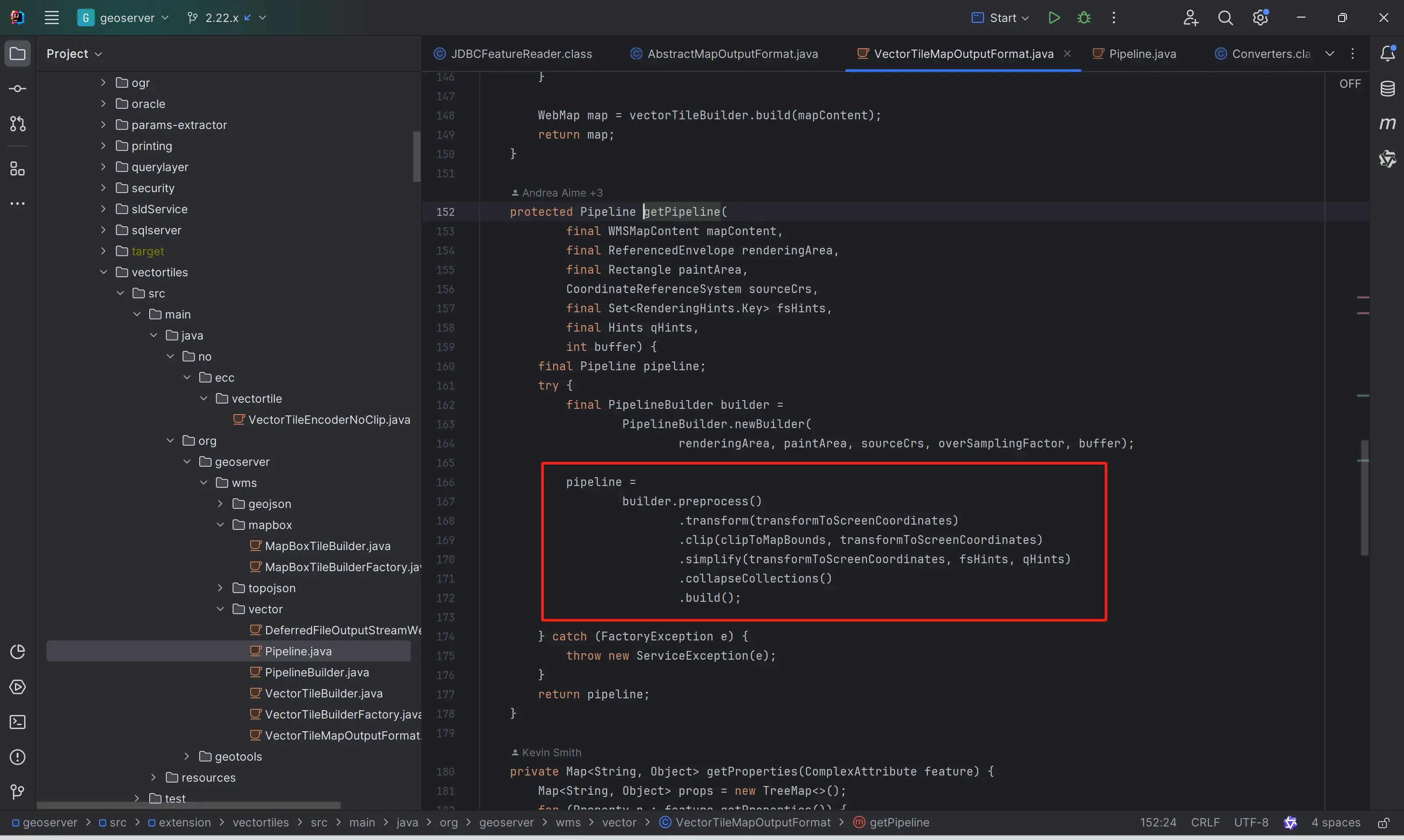
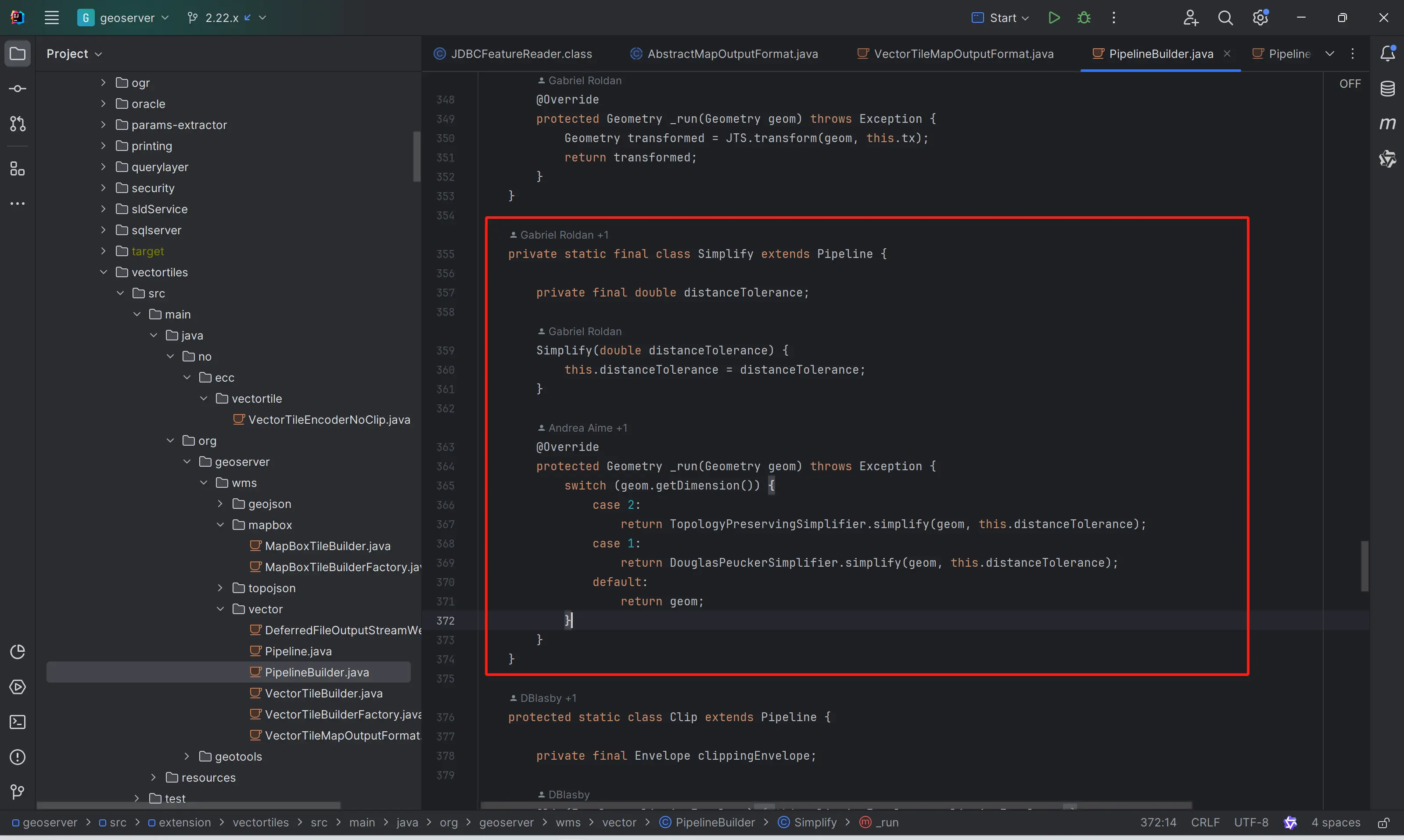
还有一个情况,其实GeoServer Vector Tile Plugin采用的矢量瓦片编码器(java-vector-tile)中其实也提供了Simplify的功能,只不过默认是关闭的。
数据分层(属性分级)
GeoServer的vector tile实现中,居然是尝试从Style(SLD)中获取到Filter的信息,用以减少数据的检索(数据库中的Filter比Java基于内存的Filter更高效),同时还提供了一个将Mapbox style转换为SLD的拓展模块。
看到这里的我很激动,感觉找到了知己一般,哈哈哈。
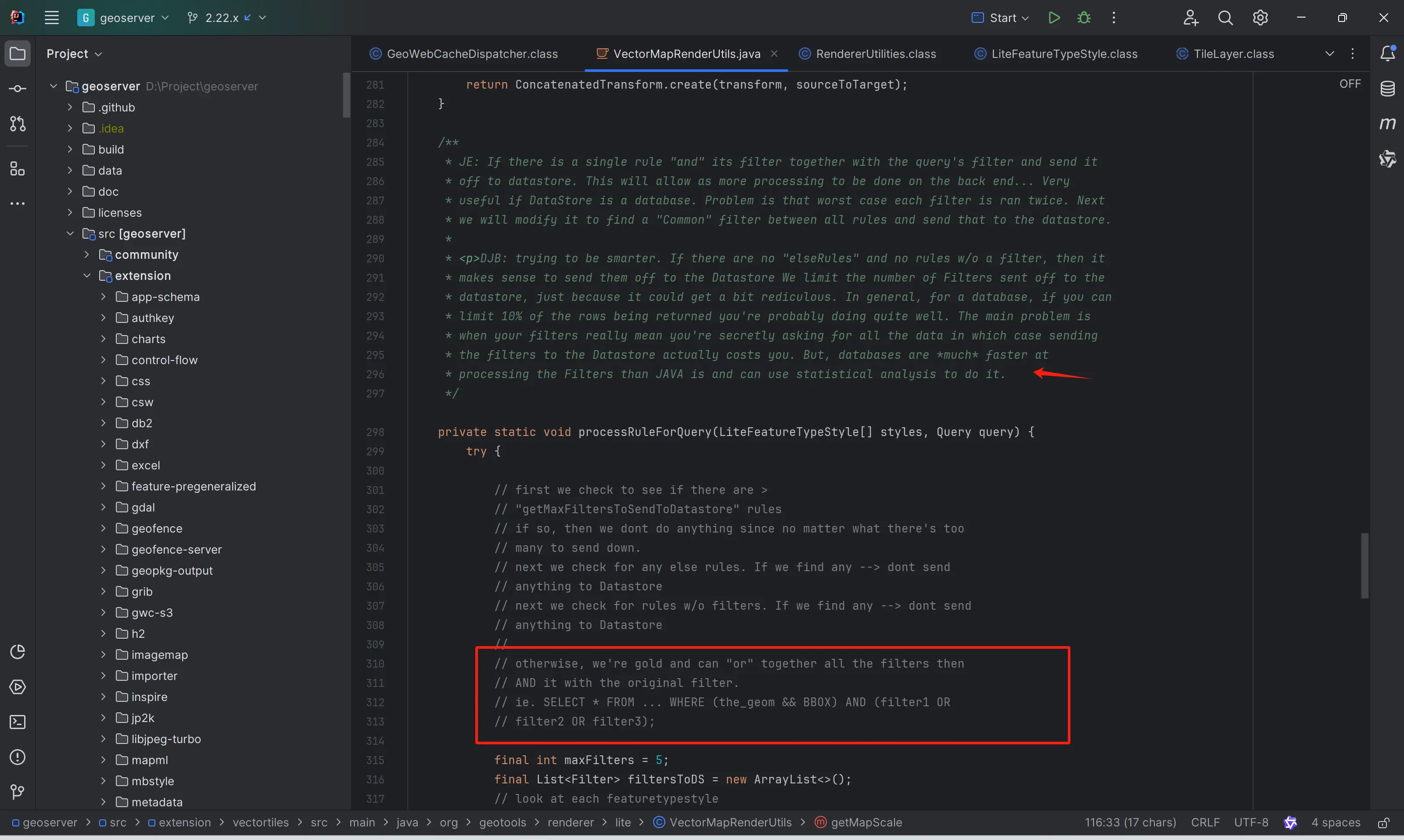
在明白真相之后的我,只能是感叹GeoServer的历史包袱太重了,但应该被敬佩。
而此时再次回头看我之前提出解析配图文件的想法,发现这种做法也是有问题的。
- 矢量瓦片技术出现,实现了一套瓦片数据可以有N种配图方案
- 矢量瓦片技术完美的分离了数据与渲染,边界清晰
所以,基于配图剥离属性分级的方式不就又将渲染与数据耦合起来,配图也就会和缓存绑定了,也就是一种配图方案一套瓦片数据了(若一旦涉及到分级部分的变化),自然是有问题的。
结论
综上所述,私以为:
在矢量切片技术下,数据当有数据本身的分层规则,不应该依赖于配图,也不应该由配图来定义。
- 分层控制当属于数据控制权限,应该归属于瓦片的生产端控制
- 在矢量瓦片时代,配图就是地图符号化的过程,对应矢量切片技术下,渲染后移到客户端的部分
- 全局分层分级策略应该是首先定义的,且应该形成公知的形态。服务端的数据控制应当严格遵循该策略,客户端可控分层范围是该策略的子集